SSAS error configurations allow for some flexible arrangements in object processing. Naively, these error configurations may be changed so that a dimension can be successfully processed however, the error configurations can have a dramatic effect on how the dimension and fact data is processed. This post examines the error configuration for duplicate attributes. In doing so, I address dimension design, its processing and the effect that the configuration has on fact and dimension data.
In this post, we use a simple geography model for illustration, with a single measure (value) against each leaf node. Note that the city Berlin appears in the states of Hessen and Saarland.
|
Structure |
Data |
|
|
|
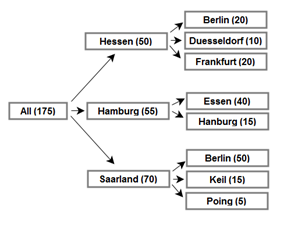

The data for the model is also very simple (with both fact data and dimension in a single table). The row_key field has been added to the table to improve the dimension appearance (design appearance). Additionally, some will note that the row_key is an excellent candidate for the [city] attribute key in this scenario, however, to keep things simple, we use attribute names as keys.
Dimension Design
Default Design (no relationships)
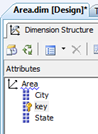
When the dimension is created it has three attributes of [key], [State] and [City]. The default behaviour of these attributes is to relate each (non-key) attribute directly to the dimensions key as below;
|
Structure |
Attribute Relationships |
|
|
|
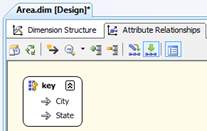
If a hierarchy is created so that state drills into city, the relationship view changes slightly and separates the attributes into distinctive nodes (as below). In this situation, the relationships have not changed as both [State] and [City] relate directly to the key. Note that the hierarchy provides a warning triangle ( ) which states that attribute relationships do not exist between levels in the hierarchy and this may decrease performance.
) which states that attribute relationships do not exist between levels in the hierarchy and this may decrease performance.
|
Structure |
Attribute Relationships |
|
|
|
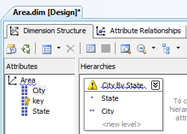

The importance of relationships is well understood and, is arguably the most important performance consideration in dimension design. Because, we expect cities to roll up to states, the relationship should be created as part of the design. This (second design) choice is for performance.
Performance Design (relationships)
When the dimension is designed with relationships (below), the warning indicator is removed from the hierarchy.
|
Structure |
Attribute Relationships |
|
|
|


Dimension Processing
Dimension processing involves many stages. For our purpose, we are primarily interested with the load of data (that is loading member data) and the effect that relationships have on processing.
The default design sends a query to the data source for each non key attribute in the dimension. These are highlighted in the first two queries in the trace below where the data for [city] and [state] is loaded. The final query holds the data for the dimension key and relates the key to the [state] and [city] attributes. Note that in this design, each attribute is directly related to the dimension key and therefore, the members for these attributes have a direct relation with the key, hence the third query must relate the key to both [state] and [city] attributes.

When the performance design dimension is processed (note the dimension fails processing), the queries sent for data mimic the attribute structure in the relationship design. That is;
- A query is sent to retrieve [State] data. This is the same as in the default design.
- A query is sent to retrieve the [city] and [state] data. Unlike the default design, this includes [state] because state has a relationship with city.
- Finally, a query is sent for [key] data and the [city] relationship. In the default design, this query also included the [state] attribute however, since [state] is related to city (and this relation is exposed in the prior query), there is no requirement for [state] data and it is excluded.

Dimension Processing Error Configuration
Under the default error configuration, the performance design dimension fails during processing with a ‘duplicate key’ error is displayed (as below).

|
This error relates to the expectation that a [city] will relate to one (and only one) [state]. The data shows that the city Berlin is found in both Hessen and Saarland. |
|
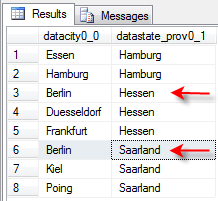
|
|
In order to process the dimension, the KeyDuplicate error configuration may be changed to IgnoreError or ReportAndContinue from the default value of ReportAndStop. However, while this may permit the dimension to process, the change in error configuration can have adverse impacts on both dimension data and fact data. |

Data Outcomes
|
When the performance dimension is processed by ignoring duplicate attribute errors, members which raise the error are dropped from the dimension. Not all members are dropped.
Berlin is not found under Hessen and the fact values do not match the expected [state] totals. Note that Hessen should sum to 50 and Saarland should sum to 70. The 20 difference relates to the 20 for Berlin which should reside in Hessen (but now resides in Saarland). |
|
|


Correcting the Outcome
A standard way of correcting this type of error is to apply a composite key to the attribute that causes the issue. In this situation, the key of the city attribute now uses both the state and city (see below) and shows the expected structure.
|
|
|


Conclusion
While the use of error configurations may permit the processing of dimensions, the outcomes of the processing operation can have unexpected results. A more certain way of managing processing is to address the underlying issue of the error at the source or through other factors in dimension design.

Great post to send to my coworkers to easily understand dup keys and one aspect of error configuration.
Pingback: SSAS Dimension Processing « manojkumarbi
Excelent post THNKS!!!!!
yeah, this was a nice and VERY clear explanation. Great work!
thanks Bill!
Paul, i have a question related to the above situation. Suppose there is a level on top of the state/city, called country. Attribute keys have been designed using composite keys. And a user hierarchy country > state > city is used. Users are now asking for an additional user hierarchy country > city. In this situation this would lead to a duplicate value of Berlin being shown on the city level, due to state being in the cities key.
At this point i’m considering to create a column duplicate of city, assign country/city as a key and use this new column in the new user country>city hierarchy and create attribute relationship accordingly. Is this the best possible solution to this problem or is there a better way to model it?
Hi Ergon
Your approach is absolutely correct – this is just the way the hierarchies work.
You cold also consider creating/using an attribute for city and have that in the hierarchy.
The city values will be fileted as youexpect but ssas will show a warning in the hierarchy (suggesting relationships). For performance it’s not optimal but it may suite your needs.
Hi Ergon
Your approach is absolutely correct – this is just the way the hierarchies work.
You cold also consider creating/using an attribute for city and have that in the hierarchy.
The city values will be fileted as youexpect but ssas will show a warning in the hierarchy (suggesting relationships). For performance it’s not optimal but it may suite your needs.
Thank you Paul
Oh one other thing .. When you say add a column, do you mean on the dsv or in the view definition? You could just create a new attribute in the dimension and use the existing dimension data
Thank you Paul, that one saves me some database work aswell.